- January 16, 2019
- Posted by: Vikas Chowdhury
- Categories:

Joseph Palenzuela from Toptal contacted YourNXT and provided us an additional resource for Modern Web Scraping with Python and Selenium
Web Scraping is a method to write a program or algorithm to extract and process a very large amount of data from the web. It’s the way of downloading structured data set from the web, selecting the required data, and pass it on to another system. For eg., you can extract some of the data from downloaded HTML content using parsers and store the required result set in JSON format in a non-relational database like MongoDB.One can achieve this using BeautifulSoup4.
In complex web pages where it’s difficult to parse HTML data or data is loading dynamically on scrolling, you can use BeautifulSoup4 with selenium and any of the web drivers(chrome/gecko).
Using BeautifulSoup4
To proceed, you need to install python 2 or 3 in your system.
To perform web scraping, you should also import the libraries shown below. The requests module is used to open URLs. The Beautiful Soup package is used to extract data from HTML files. The Beautiful Soup library’s name is bs4 which stands for Beautiful Soup, version 4.

After importing the necessary modules, you should specify the URL containing the dataset and pass it to requests.get() to get the HTML of the page.
Getting the HTML content of the page is just the first step. The next step is to create a Beautiful Soup object from the HTML. This is done by passing the HTML to the BeautifulSoup() function. The Beautiful Soup package is used to parse the HTML, that is, take the raw HTML text and break it into Python objects.

Once you get soup you can get useful information from it. For eg., you can get page title, text from this object.

You can use the find_all() method of soup to extract useful HTML tags within a webpage. To print out table rows only, pass the ‘tr’ argument in soup.find_all().
Using BeautifulSoup with Selenium
To perform web scraping, you should also import the libraries shown below. The selenium module is to automatically open a web browser using a web driver. The Beautiful Soup package is used to extract data from HTML files. The Beautiful Soup library’s name is bs4 which stands for Beautiful Soup, version 4.

Apart from this you also need to download a web driver for chrome compatible with your system.
You need to create a browser object like below and need to set chrome to headless version(Doing so allows you to run chrome in linux servers without UI).

Now you can create beautifulsoup object by following code that scrolls the webpage to get data using Selenium with chrome. Here url can be any web page url you wish to scrap.
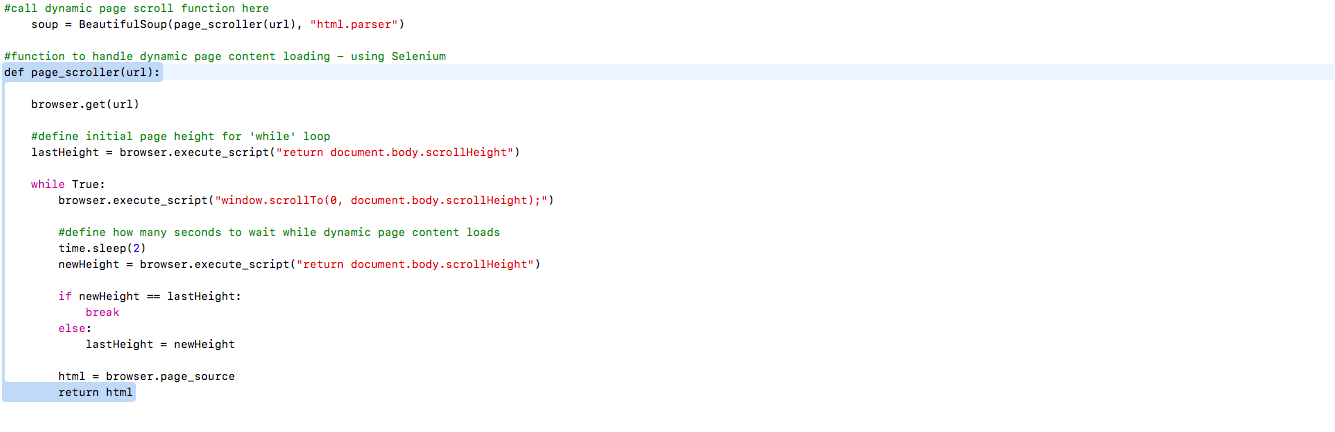
After getting soup you can parse the html content and get the desired output.You can also create json object of selected data using json.dumps(jsonObj).Here jsonObj refers to a JSON object which you can create for data manipulation.